
I have continued my study into Python programming, see part I for earlier results. The code might not be very pythonic, despite some effort to that direction. With a little sugar coating one might say that I’m being pragmatic, a cynic might tell that I lose my bad habits slowly. At least I have tried to comment a little bit, which makes it easier for me to remember what I have been attempting to do.
In the analysis I looked into the stability of the election result. This was done by a Monte Carlo analysis. Despite the fancy name in practice I just manipulated the result by introducing random changes and then calculated what the result would have been with the new vote counts.
My motive was the eternal discussion about people not voting and how an individual has little impact on the result.
The analysis went roughly like this:
- Query the database for the number of votes for each candidate and sum these to get the number of votes given to each party
- Manipulate the result and calculate a new result
- Repeat 2 many times
- Calculate the average number of seats for each party and make a note of the largest and smallest number of councilmen
- Continue from 2 using a larger deviation in the manipulation.
It would have been possible to directly query the database for the elected candidates, but I wanted to do the calculation myself and compare the result for the actual confirmed result. This gave the opportunity to check how well the algorithm works. The result I calculated was not the same for all municipalities, this is because in case of same distribution figures or within a party list with the same number of votes the result is decided by a lottery. Due to the random nature of the lottery, it’s result can not be repeated in the code. Instead I allocated the seats according to the order of an internal list.
It is good to note that the my results here are in some sense suggestive only, as the effort put to confirming that the code works correctly was not at a level that would be required for example for scientific publication.
The manipulation itself was done like this:
tot=EA[k][2]*(random.uniform(-1,1)*B[m]+1)
Or put in another way:![]() where,
where,![]()
The number of votes a party accumulated in the election was multiplied by a number that was between 0.999 and 1.001 when the delta was smallest and between 0 and 2 when the delta was largest. Each time the manipulation was done a random number was drawn for each of the parties. Drawing the random number and the manipulation was done 10 000 times for each municipality to see how the result varies for each value of B. It is good to note that selection of the number of iteration was based on the “I feel like it” method that has been criticized, sometimes harshly.
The selected manipulation method doesn’t directly match with any real situation, although it is similar for example to cases where the active members of a local election team catch the plague at a critical moment or a rich benefactor enables a particularly well funded campaign. In these cases the changes in the result might be similar to what is seen in the images below. The mean number of seats gives a hint on where the number of seats gained has mostly been, close to maximum or minimum.
The clearest result can be seen in how much must the number of votes change to change the result. In the figures parameter B is shown as “delta=x” where x is the value of B used. If the minimum and maximum number of seats (red bar in the figures) gained do not differ from the average (blue in the figures) the result has been the same for all iterations, which can be interpreted as a stable result at this level of variation in the voting behaviour.
It should be noted that because the number of votes a party got in the voting is used as basis for calculations, it is not possible to get candidates elected even with large deltas if the party got for example three votes in the actual election. On the other hand even a large number of votes quickly evaporates when the value of R is very close to minus one. When the changes in the number of votes are large, it is possible that the overall number of votes given can be larger that the number of eligible voters in the municipality.
I chose five municipalities at random and looked at their result more closely: Janakkala, Kalajoki, Karkkila, Liperi and Savukoski.
I use the commonly used abbreviations for the larger parties in the text below.
In Janakkala the number of PS councilmen could have changed with a 5 % change in the number of votes they got, in absolute terms this means 54 votes. Similarly KESK could have gotten one seat more with the same relative change, corresponding to 84 votes. With a 20 % change KD could have lost their only seat.
In Savukoski if one person more would have made their way to the polling station and voted for PS the result would have been different. PS would have gotten as many councilmen as VAS. In the real elections VAS got three times as many seats as PS. Whether this would have changed any decisions is of course a different question.
 Figure1. With a maximum change of 2 % the Janakkala result is unchanged.
Figure1. With a maximum change of 2 % the Janakkala result is unchanged.
 Figure 2. With a maximum change of 5 % the number of councilmen can change. SDP and PS could lose two seats. With these changes KESK would always gain if there was a change, although most of the time it gets the same result.
Figure 2. With a maximum change of 5 % the number of councilmen can change. SDP and PS could lose two seats. With these changes KESK would always gain if there was a change, although most of the time it gets the same result.
 Figure 3. With a maximum change of 20 % any part of the result can be different from the real one.
Figure 3. With a maximum change of 20 % any part of the result can be different from the real one.
In figures 1 through 3 increase in parameter B starts to show as larger variation in the result. In Janakkala the result is most stable for KD and the for VIHR.
 Figure 4. In Kalajoki Pro, SDP and VIHR have fairly stable results since a 10 % change wouldn’t have an effect in their number of councilmen.
Figure 4. In Kalajoki Pro, SDP and VIHR have fairly stable results since a 10 % change wouldn’t have an effect in their number of councilmen.
 Figure 5. It turns out the one VIHR seat is the most stable. KD would rather lose their seat than gain more.
Figure 5. It turns out the one VIHR seat is the most stable. KD would rather lose their seat than gain more.
 Figure 6. In Karkkila the result would first start to change between SDP and VAS at the 2 % level, SDP would lose one seat.
Figure 6. In Karkkila the result would first start to change between SDP and VAS at the 2 % level, SDP would lose one seat.
 Figure 7. At the 5 % level only KESK has a stable result.
Figure 7. At the 5 % level only KESK has a stable result.
 Figure 8. In Karkkila the parties had fairly similar results, at the 10 % level changes can be seen in all the results.
Figure 8. In Karkkila the parties had fairly similar results, at the 10 % level changes can be seen in all the results.
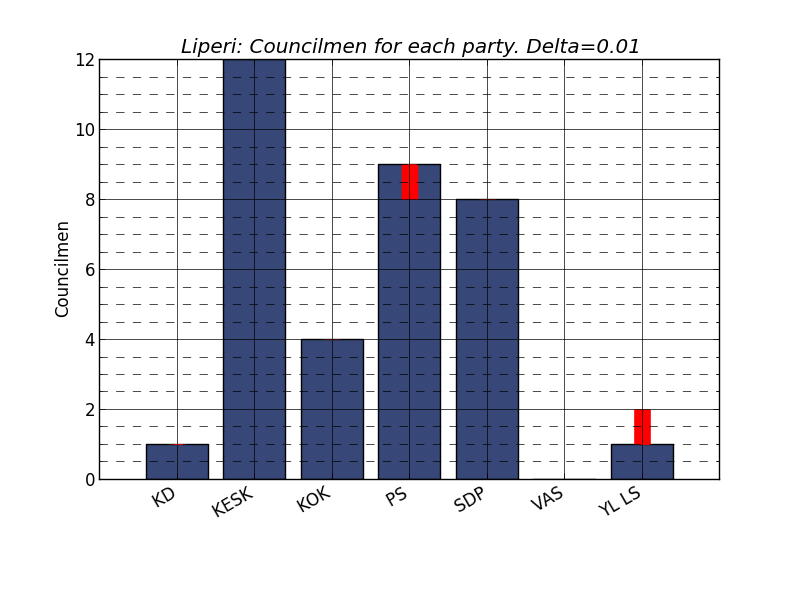 Figure 9. In Liperi the first changes can be seen between PS and YL LS at 1 % level.
Figure 9. In Liperi the first changes can be seen between PS and YL LS at 1 % level.
 Figure 10. In the Savukoski council half a percent change in the number of votes can change the result. However it would most likely not change any decisions.
Figure 10. In the Savukoski council half a percent change in the number of votes can change the result. However it would most likely not change any decisions.
 Figure 11. At 5 % level KESK could lose its majority.
Figure 11. At 5 % level KESK could lose its majority.
Table 1.




 Figure 1.
Figure 1.